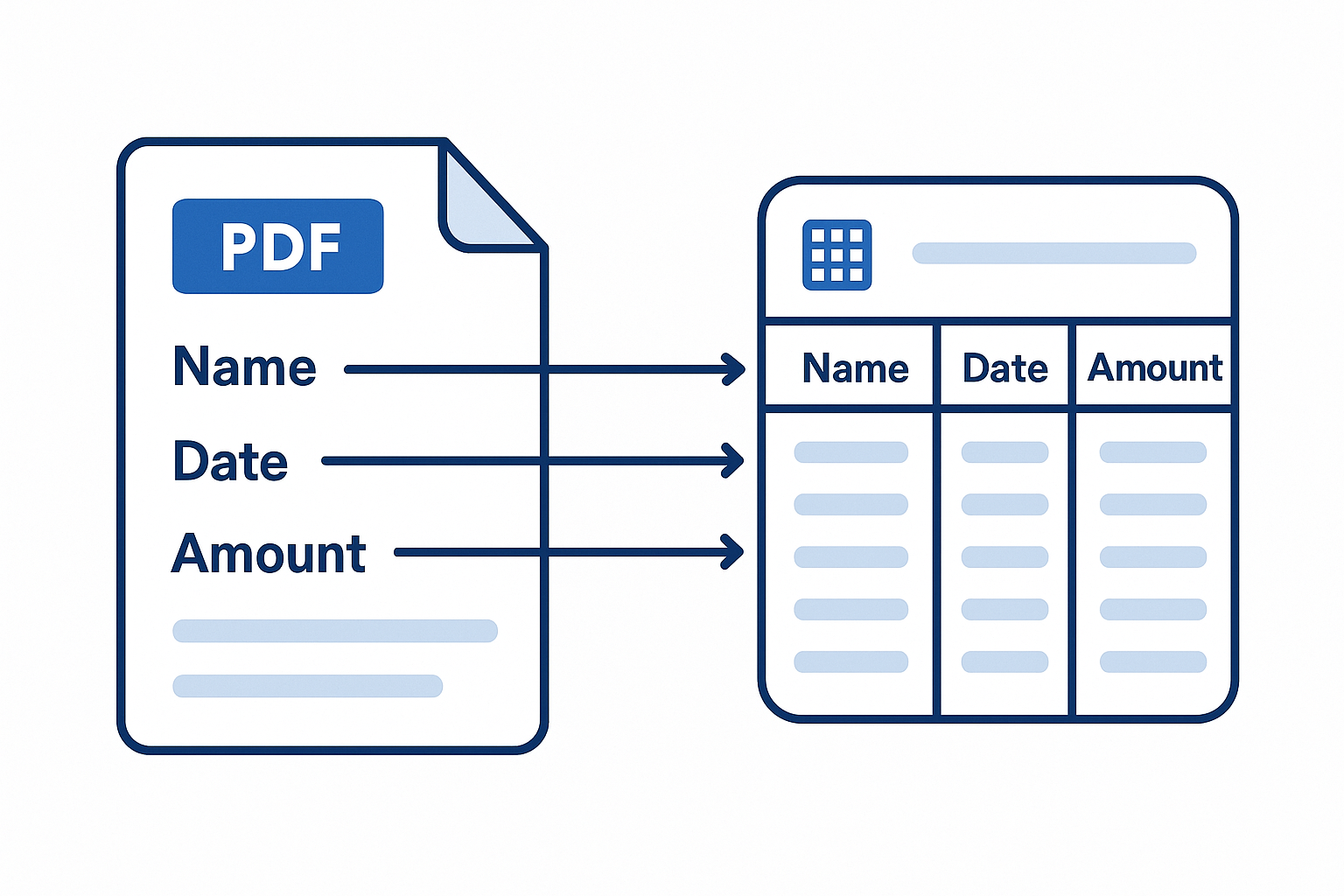
How to Use GetTextFromPDF() in FileMaker 2025

How does FileMaker 2025 help you extract text from PDFs?
Why does extracting text from PDFs matter?
Extracting text from PDF files used to be a frustrating and time-consuming task. Developers, researchers, and professionals often had to rely on cumbersome third-party tools, external plugins, or even write custom scripts just to access the information locked inside PDFs. These workarounds were complex, inconsistent, and far from seamless. Now, with a simpler, built-in solution, you can unlock valuable data directly, streamlining workflows and enabling smarter searches. Given that PDFs are so commonly used in business, they are likely the most prevalent form of unstructured data, making this new feature a powerful addition built into the platform.

🛡️ Responsible AI Note: Only extract and store PDF content if you have the legal and ethical right to do so.
What’s new in FileMaker 2025 for PDF text extraction?
FileMaker 2025 introduces the GetTextFromPDF() function—a native calculation that extracts text from PDF files stored in container fields. This turns static documents into searchable, actionable content without leaving the FileMaker ecosystem. Whether you’re indexing archived contracts, summarizing legal filings, or enriching AI interactions with document content, this feature streamlines your workflow and eliminates the need for third-party OCR tools.
🛡️ Responsible AI Note: Be transparent with users about how their documents are being parsed or used for analysis.
How does GetTextFromPDF() work?
Using GetTextFromPDF(container) is simple: point it at a container field holding a PDF, and it returns the embedded text as a plain string. You can then store that text in a field, use it for semantic search, or feed it into a Retrieval-Augmented Generation (RAG) pipeline.

Does it use AI?
The GetTextFromPDF() function itself does not use AI, but it enables AI-powered applications. / By extracting text from PDFs, it provides the raw data that can be fed into AI models for semantic search, document summarization, or Retrieval-Augmented Generation (RAG) workflows.
How does it work on different platforms?
- Mac/iOS: Uses Apple’s PDFKit, specifically the
PDFSelectionstring method, to retrieve text from PDFs. PDFKit Documentation (Apple) - Windows & Ubuntu: Uses Google’s pdfium library to parse and extract text from PDFs. Google pdfium

What are the key features?
- Support for Embedded Text: Extracts text from PDFs that contain embedded text layers, ensuring high accuracy for most modern documents.
- Plain String Output: Returns extracted text as a simple string, making it easy to store, manipulate, or process further. In conjunction with AI models, this feature becomes very powerful!
What are the limitations of GetTextFromPDF()?
While the GetTextFromPDF() function is a powerful tool, it has some limitations to keep in mind:
- Quality of Source PDF:
- The quality and structure of the source PDF file directly impact the accuracy of the extracted text. Formatting such as fonts, colors, sizes, and exact layout is not preserved in the returned text.
- No Support for Images:
- Text embedded in bitmapped image formats, such as PNG or JPG, within the PDF file will not be extracted.
- Returns “?” in Certain Cases:
- The function will return “?” if:
- The container field is empty or doesn’t contain a PDF file.
- No text is found in the PDF file.
- The PDF file is a scanned document without an embedded text layer.
- The PDF file is password-protected or cannot be read for any reason.
Understanding these limitations will help you plan your workflows effectively and ensure you use the function in scenarios where it can deliver the best results.
How is GetTextFromPDF() different from OCR?
Some may be familiar with OCR (Optical Character Recognition), a technology that converts scanned images or image-based PDFs into machine-readable text. Unlike OCR, the GetTextFromPDF() function in FileMaker 2025 extracts text directly from the embedded text layer of a PDF, without the need for image analysis. This makes it faster, more accurate, and better suited for modern PDFs that already contain selectable text.
When would you use GetTextFromPDF() vs. OCR?
| Scenario | Use GetTextFromPDF() | Use OCR |
| PDF Type | Contains an embedded text layer (e.g., digitally created PDFs, not scanned images). | Image-based or scanned PDFs with no embedded text layer. |
| Accuracy and Speed | High accuracy and speed for extracting text. | Useful for extracting text from handwritten or poorly formatted documents. |
| Tool Dependency | Avoids reliance on third-party OCR tools or external integrations. | Suitable for legacy documents or older PDFs that lack digital text. |
| Workflow Integration | Seamless solution within the FileMaker ecosystem. | Necessary for handling scanned or image-based documents. |
By understanding the type of PDF you’re working with, you can choose the right tool for the job. For most modern, digitally created PDFs, GetTextFromPDF() is the optimal choice. However, OCR remains essential for handling scanned or image-based documents.
How can you use extracted PDF text in FileMaker?
- Make documents searchable using native Find or AI-powered semantic search.
- Automatically populate data fields from structured PDFs like forms or reports.
- Add content to a RAG space for AI-powered Q&A over your PDF library.
- Summarize PDF documents using LLMs for quick previews or intelligent automation.
A typical automation pattern might include extracting the text, storing it in a text field, and feeding it to a RAG action or prompt:
Set Field [ MyTable::ExtractedText ; GetTextFromPDF(MyTable::PDFContainer) ] Perform RAG Action [ RAG Account: "MyRAG", Space ID: "Docs", From Text: MyTable::ExtractedText ]
What are the best practices for responsible use?
- Privacy: PDFs might contain sensitive or personal data. Only extract and store content if you have the legal and ethical right to do so.
- Transparency: When used in AI workflows, be clear with users about how their documents are being parsed or used for analysis.
- Accuracy: Scanned or image-based PDFs will yield incomplete or unreadable text. Always provide fallback handling.
- Security: If storing extracted text, ensure appropriate field-level access controls are in place to protect confidential data.
Why does this matter for your workflow?
The GetTextFromPDF() function unlocks an often-overlooked part of your data: the rich text buried in PDFs. With this new tool, FileMaker developers can create smarter, more searchable, and AI-friendly applications, and all without duct-taping together external services.
Where can you learn more?
- PDFKit Documentation (Apple)
- Google pdfium
- Best PDF Data Extraction Tools (somethingnewnow.net)
- PDF-Extract-Kit Review (ClickUp Blog)
- Pix2Text Overview (Medium)
Final Thoughts for Now
Ready to unlock the full value of your PDF data in FileMaker? Try the new GetTextFromPDF() function, and let us know how it transforms your workflow. For more tips, best practices, or help with automation and responsible AI, reach out to Violet Beacon.
How AI Was Used in This Post
AI supported this post by assisting with topic brainstorming, research, drafting, and proofreading. All contributions were overseen to ensure a human-centered tone.